In this tutorial, you will learn about Teradata architecture and its major components like Parsing Engine, BYNET, AMPs, and VDISK.
Teradata architecture is based on Massively Parallel Processing (MPP) architecture. The major components in Teradata are:
- Parsing Engine or PE
- BYNET
- AMPs or Access Module Processor
- VDisk
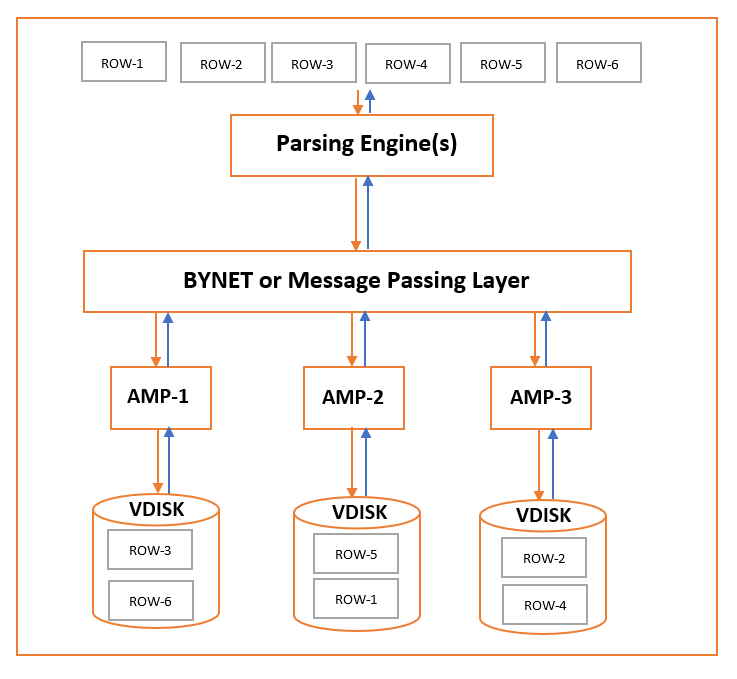
The following diagram shows the high level architecture of a typical Teradata Node.
Components of Teradata
The major components of Teradata are as follows:
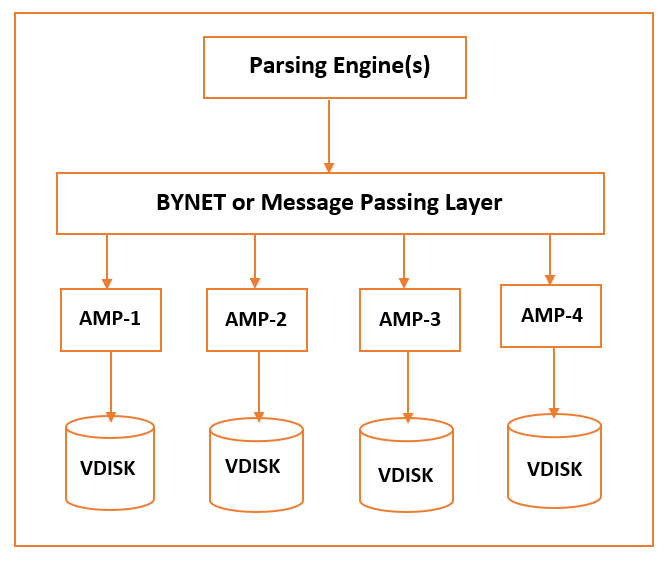
1) Node
Node is called the basic unit in any Teradata system. Each individual server in Teradata is referred to as a node. Each node is the combination of the operating system, memory, storage disk, and own copy of Teradata RDBMS software. One or more nodes along with other hardware devices such as network switches create a cabinet.
2) Parsing Engine(PE)
Parsing Engines(PE) is the component to which users connect first. PE receives queries from the client and creates an efficient execution plan. The responsibilities of the parsing engine can be divided as follows:
- Receives the queries from the client.
- The parser checks the syntax of the query. If the query is syntactically correct then the query will be passed to the session handler.
- The responsibility of the session handler is to do semantic and security checking. As part of the semantic check, it will check if the objects requested in the query exist in the database or not. It also checks if the user has the appropriate rights to the requested objects.
- Then the optimizer creates the best possible and optimized plan to execute the query.
- The dispatcher dispatches the query to the BYNET and AMPs.
- After processing the query receives the result from the AMPs and sends it back to the client.
3) Message Passing Layer or BYNET
Message Passing Layer also called BYNET works as a networking layer in the Teradata system. It acts as a communication channel between PEs and AMPs also between different nodes. It receives the execution plans from the parsing engine and sends them to the AMPs. Similarly, it receives results from the AMPs and sends them back to the parsing engine.
Actually, there are two BYNET available in the Teradata system; “BYNET 0” and “BYNET 1”. But they are referred to as a single BYNET system. Following is the benefit of having two BYNET.
- If one BYNET fails, the second one can take its place.
- When data is large, both BYNETs can be made functional which improves the communication between PE and AMPs, thus fastening the process.
4) Access Module Processor (AMP)
Access Module Processor or AMPs also called virtual processors (vprocs) are responsible for processing, storing, and retrieving the data. AMPs receives data and execution plans from the parsing engine performs processing like data type conversion, aggregation, filtering, sorting, and stores the data into the disk associated with it. Each AMP is associated with a disk and allowed to read and write data only on its own disk. This is the reason it’s called “SHARED NOTHING ARCHITECTURE“.
5) Virtual Disk or VDisk
Teradata offers a set of Virtual Disks for each AMP. Virtual disks are made from the physical disk. The storage area of each AMP is called as Virtual Disk or Vdisk. The steps for executing the query are below:
- The query receives the parsing engine first from the client.
- The parsing engine does the security, semantic, and syntax checks and finds out the best optimal plan to execute the query.
- The table rows are distributed on the AMP and the data is retrieved from the disk.
- The AMP sends back the data through BYNET to PE.
- PE returns back the data to the user.
Storage Architecture
When a client executes any query to insert data, the parsing engine after checking the validity of the query sends the records to the BYNET. After receiving the data, BYNET sends the records to the target AMP. AMP stores the records into its own disk. The following diagram shows the storage architecture of the Teradata system.
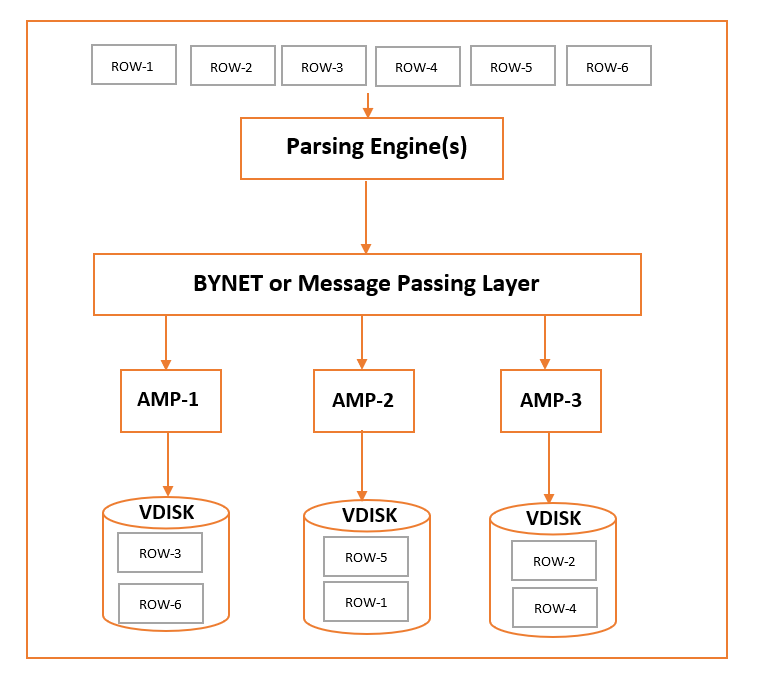
Retrieval Architecture
Whenever a client sends any query to retrieve records, the parsing engine prepares the optimal query plan and sends the request to the BYNET. BYNET sends the request to the appropriate AMPs. Then AMPs search in the disk and find the records and send it to the BYNET. BYNET will send the records to the parson engine and subsequently sends the records to the client. Following is the storage architecture of the Teradata system.